Machine Learning
Sistemas de recomendación basados en contenido (Content-Based)
En este post crearemos un sistema de recomendación de documentos, para ello nos basaremos en uno de los tipos de sistemas de recomendación mas extendidos: Content-Based. Vectorizaremos el artículo para luego utilizar los tags extraídos automáticamente para calcular la similitud entre ellos.
Esta entrada es una parte de la charla que se dio para el MeetUp de Redradix sobre sistemas de recomendación. El material de la charla anterior está alojado en mi github
Content Based
Se dice que un sistema de recomendación es del tipo Content-Based cuando está basado únicamente en las características del producto y no en la valoración del usuario al producto.
Para ello, tenemos que describir el producto de una manera en la que se pueda realizar una relación entre productos, es decir, tenemos que vectorizar el producto (extracción de tags o atributos) para luego medir la similitud apoyándonos en los atributos extraídos.
Antes de empezar a picar nuestro Content-Based en python, vamos a detallar dos conceptos claves: extracción de atributos y la similitud .
Extracción de atributos
Para que nuestro modelo pueda procesar estos documentos necesitamos que los documentos se describan por unos vectores de atributos.
Un ejemplo sería vectorizar los artículos de la Wikipedia: extraemos todas las palabras de cada uno de los artículos (palabras >> atributos del artículo) para luego ponderar cada uno de ellos. La idea que subyace es que artículos similares tendrán atributos parecidos.
- Calculamos las ocurrencias: Extraemos las ocurrencias y eliminamos las palabras carentes de importancia (stopwords) además de los números, puesto que pierden el significado fuera de su contexto
- Desde las ocurrencias a las frecuencias: Normalizamos y ponderamos cada ocurrencia por medio de tf-idf.
| TF | Pesos de TF | TF-IDF | Pesos de TF-IDF | TF-IDF Con Filtrado | Pesos de TF-IDF Con Filtrado |
|---|---|---|---|---|---|
| the | 0.563848 | the | 0.245980 | billboard | 0.230409 |
| in | 0.375898 | billboard | 0.195711 | john | 0.223674 |
| and | 0.313249 | john | 0.189990 | elton | 0.219654 |
| of | 0.271482 | elton | 0.186575 | furnish | 0.200891 |
| has | 0.187949 | furnish | 0.170638 | songwriters | 0.141425 |
| he | 0.146183 | in | 0.164139 | award | 0.141251 |
| john | 0.146183 | and | 0.136804 | top | 0.140106 |
| on | 0.125299 | songwriters | 0.120128 | aids | 0.132142 |
Top Atributos para la bibliografía de Elton John
Con TF hemos normalizado las ocurrencias para eliminar la discrepancia entre documentos con distinto tamaño. TF-IDF hemos refinado los pesos teniendo en cuenta no solo las ocurrencias en el documento sino en el resto, de esta manera se puede decir que el algoritmo da prioridad a las palabras que aportan información. Por último, antes de aplicar tf-idf, hemos filtrado tanto números como stopwords
Métrica de similitud
Hay muchas clases de métricas, cada una se ajustará mejor para un caso que para otro. En la vida real utilizamos normalmente para medir la distancia entre dos objetos la métrica euclidiana, pero esta misma métrica no seria buena elección en nuestro sistema de recomendación.
¿Nosotros que clase de métrica queremos? ¿Una que solamente tenga en cuenta la dirección del vector o también la magnitud?
Si lo pensamos la respuesta es sencilla: únicamente la dirección, es decir, medir cuanto de alineado están los gustos de cada usuario o los atributos de cada elemento y no tener en cuenta la magnitud (si un usuario es más exigente que otro o si un documento tiene mas palabras que otro)
Por ello vamos a utilizar la similitud del coseno (cosine) para que la magnitud de los atributos no se tenga en cuenta en el cálculo de la similitud sino únicamente el ángulo que separa a los vectores que definen el perfil.
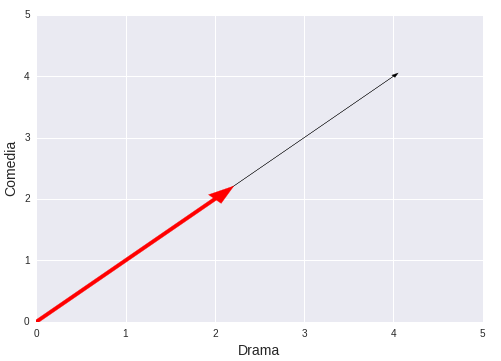
Similitudes entre usuarios
Si realizamos el cálculo de la similitud por medio del cosine, el resultado sería que son usuarios idénticos, es decir, 1.
Modelo
Uniendo las piezas anteriores, ya podemos formar paso a paso nuestro sistema de recomendación en python.
Además, vamos a generar una clase que sintetice todo lo anterior y con solo dos métodos fit y predict tengamos nuestro modelo en python listo para usarlo.
Modelo
Utilizando las funcionalidades de Sklearn, en pocas líneas tenemos nuestro modelo de recomendación de artículos.
Demostración
Vamos a poner en práctica lo aprendido viéndolo desde dos enfoques distintos. Un sistema de recomendación de bibliografías de famosos que nos ayudará bien a buscar las bibliografías mas relevantes a partir de unos tags (simulando un buscador) o recuperar los famosos que tengas más similitud con otro (simulando un sistema de recomendación como amazon).
Resultados
En este ejemplo hemos utilizado nuestro sistema de recomendación de artículos para una búsqueda de personajes y para relacionar famosos similares.
Notas finales
En esta entrada hemos visto los conceptos y pautas para diseñar nuestro propio sistema de recomendación basado en contenidos.
Otro de los sistemas mas extendidos sería Collaborative-Filtering o filtrado colaborativo: Utilizar el historial de valoraciones que ha realizado cada usuario para poder identificar las preferencias de cada uno. Se verá en la siguiente entrada.
Por último, una vez visto los dos tipos de sistemas de recomendación mas extendidos nos animaremos a construir un sistema híbrido entre Content-Based y Collaborative-Filtering para aunar lo mejorcito de cada uno y así salvar los problemas como el arranque en frío (cold start)
